Validations across micro-services
On my day-job as a consultant for GROUP9 we had an interesting discussion on how to handle validations across micro-services. Let's look at this in the context of a fictionalized example.








Example: amazon selling for other companies
The case we were discussing was the typical case of referential integrity between two objects. Imagine this: we're Amazon, and being a large e-commerce platform, we want to enable other sellers to use our platform to sell their products, while we handle all the logistics (and of course get a percentage on every sale 😁). To achieve this, we come to an agreement with a seller after some negotiations, e.g. agreeing on the commission percentage we receive on every sale. During these negations, we can add some of the products of that seller to our platform, show them the pricing, additional information etc, so the seller can have an idea what his products would look like when promoted on our platform.
Being Amazon, we of course have a micro-services landscape to support our services. In our landscape we have 2 services (probably more, but for the intent of this example, we only need 2). These services are shown in the overview below:

The agreement service registers the agreements we make with other sellers. Clearly, this is not a service regular customers see when they access amazon.com. The other service, our product service is of course used by our website service to show the various products we sell. So, in our example we would first register (a draft version of) the agreement with our seller in the Agreement service, and we would add some of his products to our product service, so he can see what we're about to sell. The product-service therefore would have a dependency on the agreement-service. Our services would offer basic data-editing capabilities, like adding, editing and removing agreements.

Enter... validations
However, we will have an issue when we start removing agreements. Those agreements are needed to calculate the price for our products. Therefore, if we remove an agreement, we won't be able to show the correct prices for our products and can't sell them anymore. Worse, our website would probably crash due to a lack of the data being available. Being Amazon, this is unacceptable. So, our initial thought is to add validations: we should not be able remove agreements if there are products which depend on them. This is the problem we are going to solve in this blogpost.
Lets start with how to solve this in the "good old days" of monolithic applications. When using a monolithic application, we could easily use referential integrity of the database (foreign keys), or we could perform a query on the other table, to see if there were references present (i.e. in case we wanted to give the user some visual cue instead of just showing an error). In the days of micro-services, where each service has its own database this is of course not possible anymore (assuming these entities were in different micro-services).
One could for example create rest-calls on the products service. This rest-call can then be called by the agreements service to check if there are still products present which refer to this agreement. If that is the case, we can provide a visual cue the agreement cannot be deleted or an error message in case the user tries to delete the agreement.

The downside of this approach is probably clear: we have effectively added a bi-directional dependency between the agreement and the product service. Our services have effectively become more tightly coupled. We can of course use something like messaging to reduce the technical coupling between the services, but that doesn't reduce the functional coupling between the services; the dependency is still there.
Clearly, in our quest for decoupled services, this is something we want to avoid. How can we remove both the functional (and consequently the technical dependency)? How can we make this dependency uni-directional again? 🤨
Validations are often more complex than you think
As we still have a functional coupling between the services, it's also worthwhile to try to solve this at the functional side. The question here is mainly: why would we want to remove the agreements in the first place? We could come up with some reasons why:
- We want to stop doing business with a certain supplier, however in this case we would probably not want to remove the agreement physically, but just mark it as discontinued.
- Once we stop doing business we want to clear our databases to adhere to privacy requirements, so we actually do want to physically remove the agreement. However, in this case we cannot remove the products, as this would remove the order information too, which our customers might need.
- The seller might decide during the negotiations he doesn't want to actually sell his products via amazon.com. In this case, we want to remove both the agreement and the products.
Looking at these requirements, we can see that the way we want to handle the whole concept of deletion of the agreements, actually really depends on the context of what the user is working on.This context consists of two parts:
- High-level, there is a business process going on. This business process defines the intent of the user: what does he want to achieve
- Based on the high-level business process, there are various actions we want to perform, which might have a different effect on the system. These consequences can then be handled by other parts of the system. For example, the action is to stop the negotiations, the consequence is to remove the products of that seller.
In our simple, data-entry (CRUD) style application, we are clearly lacking this context. The data-entry based (CRUD) system only has a few operations: Create new agreements, Update agreements or Delete agreements. The system has no way to know the context we are working in, and thus cannot determine which actions can be legally performed given the state of the system. It basically allows you to change anything at any time and can't tell one Delete operation from another.
As the system has no knowledge of this context (it only exists in the head of the user), the system cannot take the appropriate action and support the user, without going out to all other parts of the system to collect and interpret the situation. The only thing we can do in this setup, is just to prevent the user from wrecking the system. The lack of context, combined with a need for users to have these kinds of validations, is often a major cause why these kinds of systems often become quite complex and hard to maintain in the long run. We need that bi-directional communication to prevent errors, but now our system becomes a mess.
Doesn't really feel satisfactory 🤔. How can we improve on this? How can we do this better, maybe even support the user?
Process driven systems to the rescue
Apart from building a system in a CRUD like way, there are also other ways to build systems. One such way is to develop the system in a process-driven way, adding the needed context for the system. In such a system, we define a business process, as a software artifact. Such a business process is often expressed as a BPMN model, which is executed by a Process engine like Camunda. I won't fully dive into the details of building process driven systems in this post. The Camunda site offers some nice resources, and I highly recommend the blog of my colleague who specializes on this topic.
Process-driven architectures for a system can be nicely connected to systems developed using the principles of Domain Driven Design. Given the analysis above of the needed context,
this would look like:
- The running business process provides the high-level context. Determining which step we need to do at each stage of the process. Whenever we need user-interaction, a user task is started.
- The concepts from DDD, the Business methods on our Aggregates, provide the various actions we can perform. By definition of DDD, these business methods result into Domain Events, which we can employ to determine the consequences of our actions. The process is often the component responsible for translating Domain Events into new Commands.
Ok, phew 😅, that was a lot of information to digest, and quite some theoretical concepts. What would this look like in practice, in our example?
Let's see this in practice!
First, let's start with our business process, as shown below. The dotted lines are meant to indicate we only show a part of the negotiations-process, not the full process. In the proces we see the user has a task to finalize the agreement. Here he can choose to finalize the agreement, if the supplier agrees with all our terms, or cancel the negotiations.
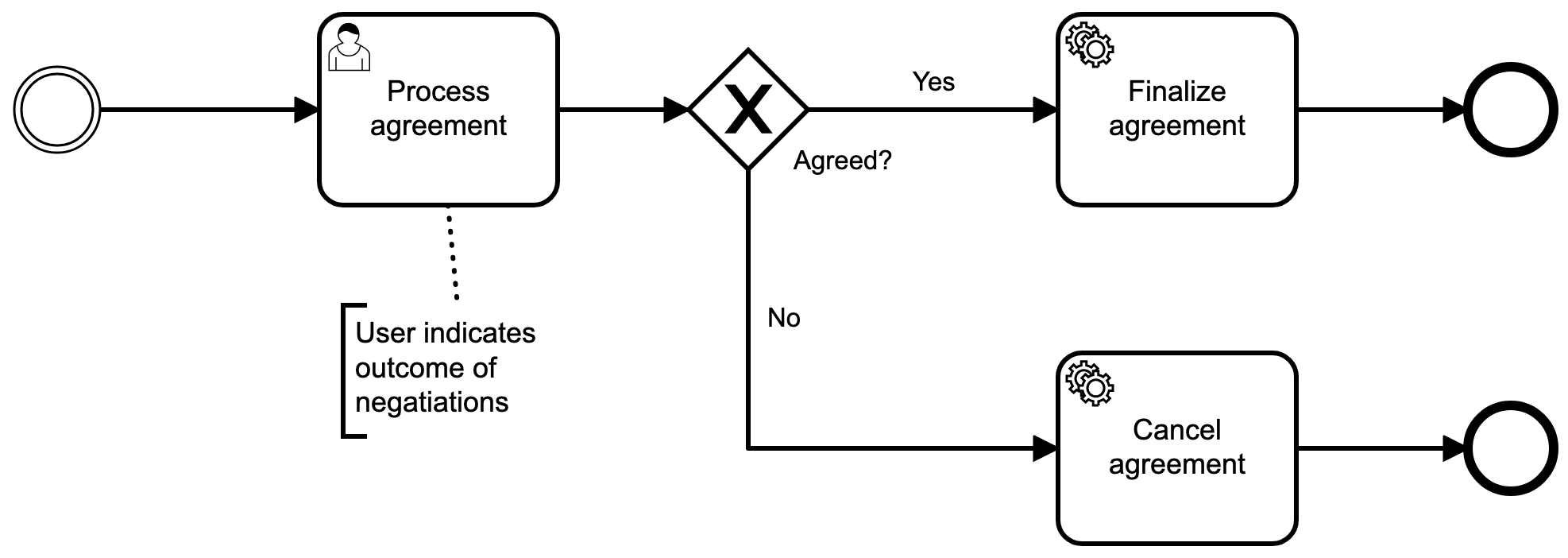
To support the user task, we can create a very simple screen, allowing him to perform the two actions we just indicated: finalize or cancel negotiations. The task screen can be very simple: it only needs to show some context to the user so he knows what agreement he's working on, and two buttons to perform the actions. My colleague will have a blog post soon expanding on this topic. Once it's live I'll update this blog to include the link.

The two service-tasks (the steps with the cog-wheels in the process) are automated steps which call onto our Aggregates. Our Aggregate emits a Domain event based on that. Important to note, is that the domain event emitted is specific to our action. So there won't be a "Agreement Deleted" event, but instead a "Negotiations Cancelled" event or a "Agreement Discontinued" event.
The product service in turn, listens for these events. We DESIGN the system that way, because we KNOW that THESE events are relevant to this service because it enacts actions to enforce consequences. These are the rules of the business. Technically, we can of course solve this using something like JMS or Kafka to ensure technical coupling. In this setup, the agreement service is unaware of who is listening to these events. Moreover, the context we added to these events allows the product service to take appropriate action:
- In case of a "Negotiation Cancelled", we just remove all products of that supplier
- In case of a " Agreement Discontinued", we disconnect them from the agreement, mark them as not for sale anymore, but still provide our users with the needed information.
In this way, we are also able to solve the functional coupling between our services. Effectively, adding context allows us to make the connection uni-directional again. As a bonus, we can also support our user better, as removing or disconnecting the products is something the system can handle for us, reducing the amount of manual labour our user needs to do.

Note: there is an extra bonus to using these concrete events instead of the more generic Create/Update/Delete actions. By using these events, and as our process engine stories the history of the processes executed, we can understand afterwards why certain actions were performed. This can often be beneficial for the business to understand and improve their own processes.
Conclusion
In complex systems, the number of validations we need to enforce can often result in a tightly coupled microservices architecture (a.k.a. Distributed Monolith, which is an anti-pattern), despite all technical measures we can take. Growing to a real loosely coupled architecture often requires adding context, as often quite some validations just disappear if context is added and we understand what the consequences of our actions are given that context.
Process-driven architectures, powered by employing principles from Domain Driven Design allow creation of micro-service architectures which are truly loosely coupled, both in a functional and a technical way. Also, by removing all these unneeded validations, we end up with simpler, better maintainable systems, often cheaper in the long run than the data-driven counterparts we started with.
Note: just to be completely clear, I'm not advocating the usage of business processes and DDD for any system. These types of architectures can be quite complex, and are optimized to tackle and cope with complex use-cases. Simple systems, for example an address book for your Soccer-club probably wouldn't benefit much from these kinds of architectures. You can of course build a simple system win this way, but sometimes the benefits don't outweigh e.g. the startup costs. For these kinds of use-cases, data-entry style applications are perfectly fine to use.
Finally, if you're interested in further information why validations are so complex, especially in an enterprise context, I highly recommend this video by Udi Dahan, where he talks about the bane of using "if-statements" in your code, a talk I was happy to have witnessed live at DDD Europe.

Comments
Post a Comment